
Scalable NYC Taxi Trip Duration Prediction using AWS EMR & PySpark
Personal Project
3 month
Data Mining

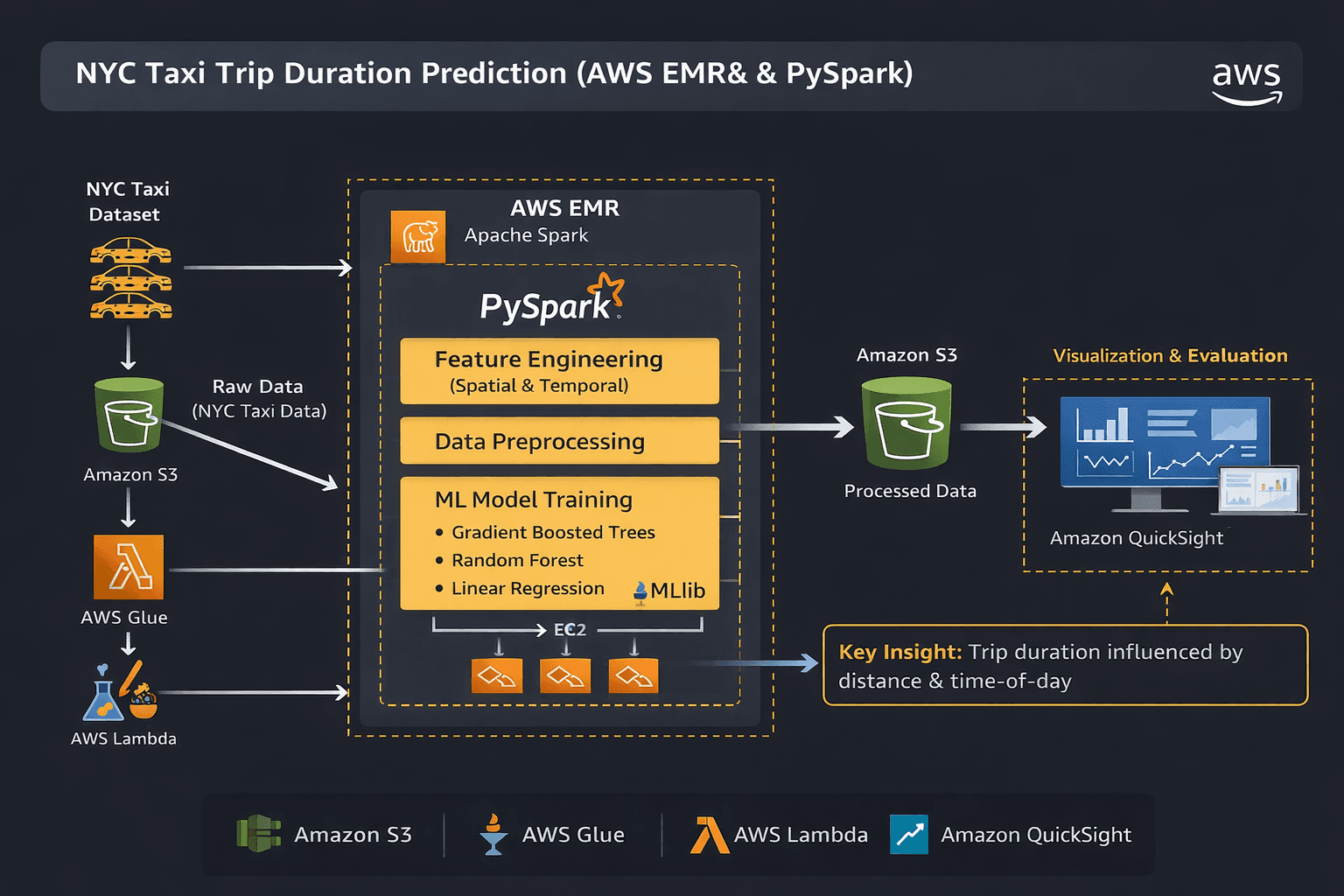
My Approach: Scalable Data Engineering & ML Pipeline
I designed and implemented a distributed data processing and machine learning pipeline using PySpark on AWS EMR to handle large-scale NYC taxi trip data. The system was built to efficiently process millions of records by leveraging parallel computation, ensuring scalability and fault tolerance.
A strong emphasis was placed on feature engineering, where temporal and spatial features were extracted to capture real-world traffic patterns. I implemented a modular ML pipeline using Spark MLlib, enabling efficient training and comparison of multiple models while maintaining performance at scale.
Vision and Innovation
This project lays the foundation for a real-time intelligent mobility system capable of predicting travel times with high accuracy. By integrating external data sources such as traffic conditions, weather, and routing APIs, the system can evolve into a production-grade solution for ride-sharing platforms, logistics optimization, and smart city infrastructure.
The long-term vision is to transition from batch processing to real-time streaming (e.g., Spark Streaming / Kafka), enabling dynamic and adaptive predictions.
Identifying System-Level Challenges
One of the key challenges was processing high-volume data efficiently while maintaining low latency and scalability. Distributed systems introduce complexities such as data partitioning, task scheduling, and resource optimization.
Additionally, the dataset lacked critical real-world variables (traffic congestion, weather conditions), resulting in low model explainability (low R²). Handling skewed distributions and outliers further increased modeling complexity.
Engineering Solutions & Optimization
To address scalability, I utilized AWS EMR to distribute workloads across multiple nodes, significantly reducing processing time. Data pipelines were optimized using PySpark transformations and actions, ensuring efficient execution.
Feature engineering techniques were applied to enhance predictive power, including distance approximation and temporal decomposition. Multiple models were evaluated, with Gradient Boosted Trees demonstrating relatively better performance due to its ability to capture non-linear relationships.
Model performance was continuously validated using RMSE, MAE, and R², and residual analysis was performed to understand prediction errors and improve robustness..
Product Thinking & User-Centric Design
The system was designed with real-world applications in mind, focusing on usability for transportation platforms and analytics teams. The architecture supports integration with dashboards and APIs, enabling stakeholders to derive actionable insights from predictions.
By visualizing trip patterns and model outputs, the system translates complex data into intuitive insights, supporting data-driven decision-making.
Business Impact & Use Cases
Enables accurate travel time estimation for ride-sharing platforms (Uber, Lyft)
Supports route optimization and demand forecasting
Provides insights for traffic management and smart city planning
Demonstrates scalable architecture applicable to large-scale data systems.
Meeting Real-World Needs
This project addresses the growing need for scalable predictive systems in urban mobility. By combining big data processing with machine learning, it highlights how organizations can leverage data to improve operational efficiency and user experience.
The architecture is designed to be extensible, allowing future integration of real-time data streams and advanced models, making it adaptable to evolving industry requirements.

